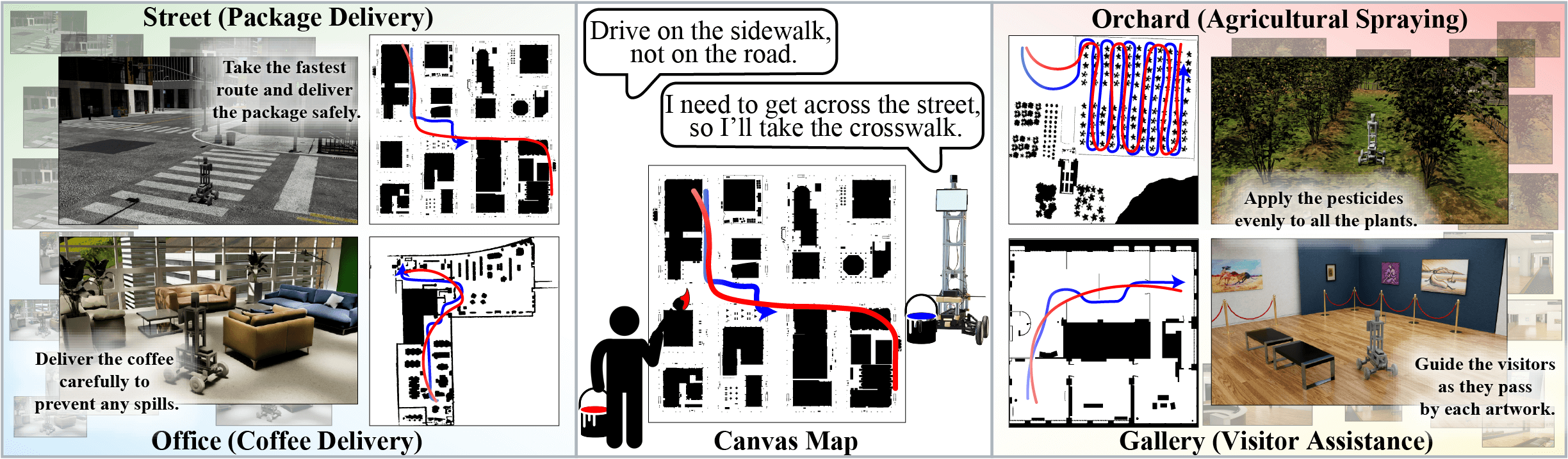
CANVAS is a novel framework for commonsense-aware robot navigation that excels in both simulated and real-world environments.
Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans.
To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications
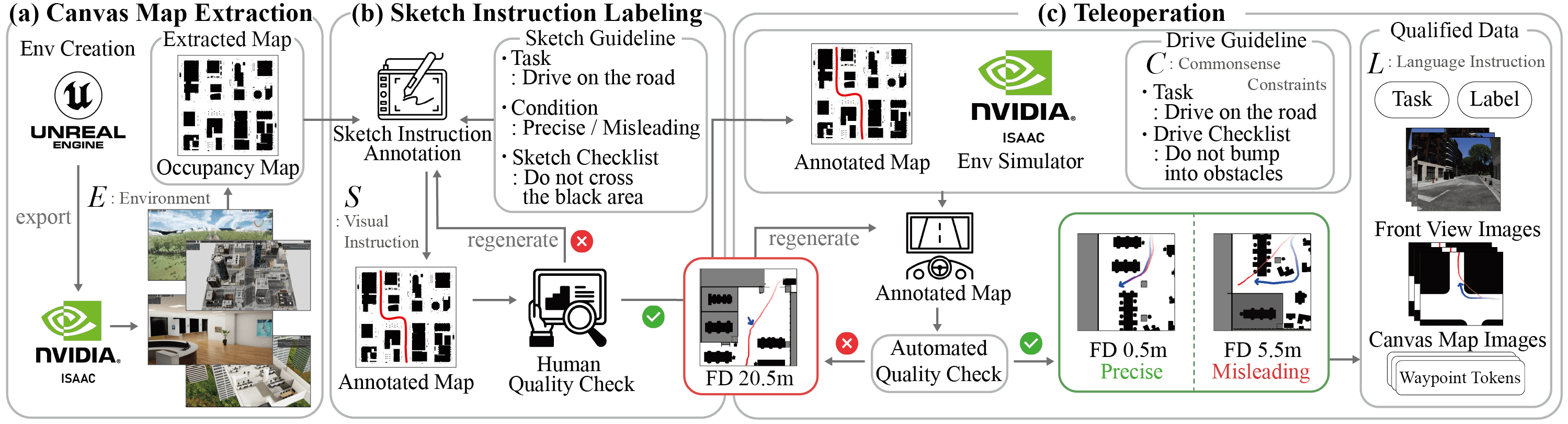
The COMMAND dataset is a comprehensive dataset that includes human-annotated navigation results spanning over 48 hours and 219 kilometers, specifically designed to train commonsense-aware navigation systems in simulated environments.
|
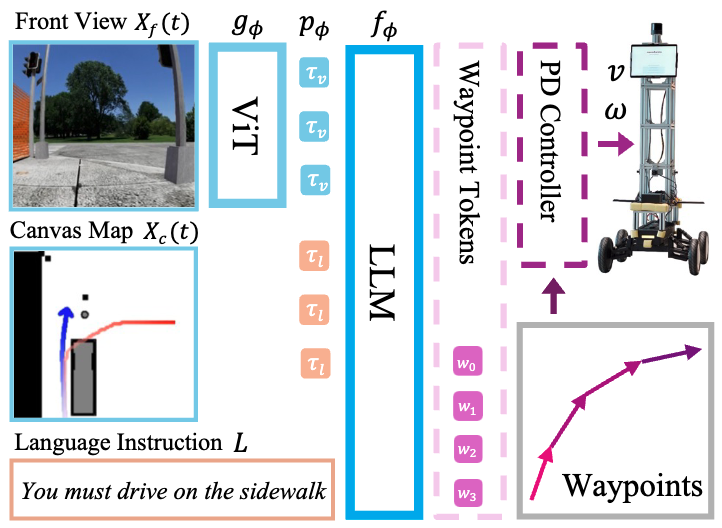
CANVAS is a vision language action(VLA) model that utilizes a vision language model with a waypoint tokenizer to generate navigation waypoints The front view image Xf (t) and canvas map image Xc(t) are processed through a vision encoder gϕ(·). Both the visual tokens τv and language tokens τl are then fed into the large language model denoted as fϕ(·), which outputs the waypoint tokens [w0, w1, w2, w3] = fϕ(τv, τl) By treating navigation as a classification task, CANVAS can manage multimodal distributions, enhancing both stability and accuracy in complex environments. |
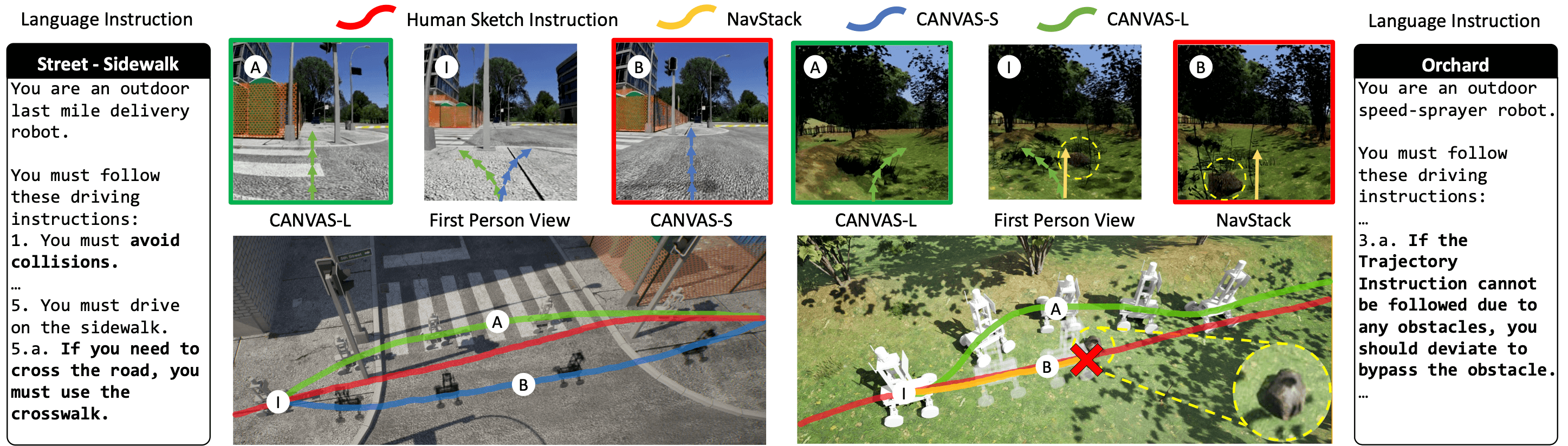
The left side of the figure compares CANVAS-L and CANVAS-S, showing CANVAS-L using the crosswalk despite a misleading sketch instruction. The right side compares CANVAS-L and NavStack, illustrating CANVAS-L avoiding small obstacles, such as rocks.
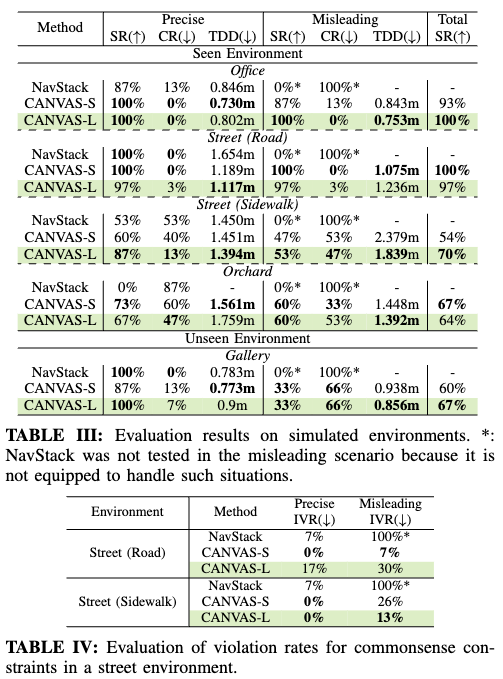
In all of environments, including unseen environments (gallery), CANVAS demonstrates a success rate of over 67%.
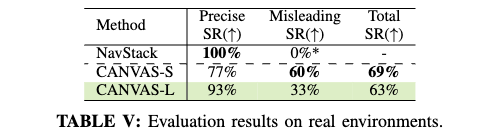
In real, even though it was trained only on simulator data, CANVAS also demonstrates a success rate of 69%
@article{choi2024canvas,
title={CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction},
author={Choi, Suhwan and Cho, Yongjun and Kim, Minchan and Jung, Jaeyoon and Joe, Myunchul and Park, Yubeen and Kim, Minseo and Kim, Sungwoong and Lee, Sungjae and Park, Hwiseong and others},
journal={arXiv preprint arXiv:2410.01273},
year={2024}
}